For the past two years, AI development has followed a deceptively simple playbook: stuff everything into the prompt. The logic seemed sound, if Claude can handle 200K tokens, why not load every policy document, SOP, and edge case directly into context?
This approach worked for demos. It fails in production.
We’re now seeing the limits of what I call “prompt maximalism”, the belief that bigger context windows automatically translate to better agent performance. They don’t. Context capacity isn’t the same as attention capacity, and at scale, monolithic prompts create systems that are slow, expensive, and unreliable.
The next evolution in AI architecture isn’t about larger prompts. It’s about structured modularity. It’s the shift from treating agents as prompt-tuned black boxes to treating them as engineered software systems with defined interfaces, isolated capabilities, and version-controlled logic.
This isn’t theoretical. We’re seeing engineering teams hit these limits right now as they move from prototype to production scale.
What Makes Prompt Stuffing Fail at Production Scale?
The promise of massive context windows was compelling: just include everything the agent might need, and it will figure out what’s relevant. But production workloads expose three fundamental problems with this approach.
- The Latency Tax Compounds with Every Interaction: When you embed 100K tokens of instructions into the system prompt, the model must process that entire payload on every turn. For simple interactions, “What’s the status of ticket #4821?”, you’re paying the same computational overhead as complex multi-step reasoning tasks. Time-to-first-token (TTFT) degrades from milliseconds to seconds, and for agentic workflows that require multiple sequential calls, this latency compounds into user-visible lag.
- Reasoning Quality Degrades in Proportion to Context Noise: Research on “lost in the middle” phenomena shows that models struggle to maintain attention across massive contexts. Critical instructions buried in the middle of a 50K-token prompt get ignored or misweighted. We’ve seen production systems where agents would correctly execute a task 95% of the time with a focused 2K-token prompt, but drop to 70% accuracy when that same instruction was embedded in a 100K-token context filled with tangentially related policies.
- The Cost Structure Becomes Unsustainable: Every token in your prompt gets billed on every API call. If your “Customer Support Agent” loads your entire knowledge base into context, you’re paying to process 100K tokens whether the user asks a complex question or just types “hello.” At Claude’s API pricing, this turns simple interactions into expensive operations, and high-volume production workloads become economically prohibitive.
These aren’t edge cases. They’re architectural constraints that force a different approach.
What Are Anthropic Agent Skills and How Do They Work?
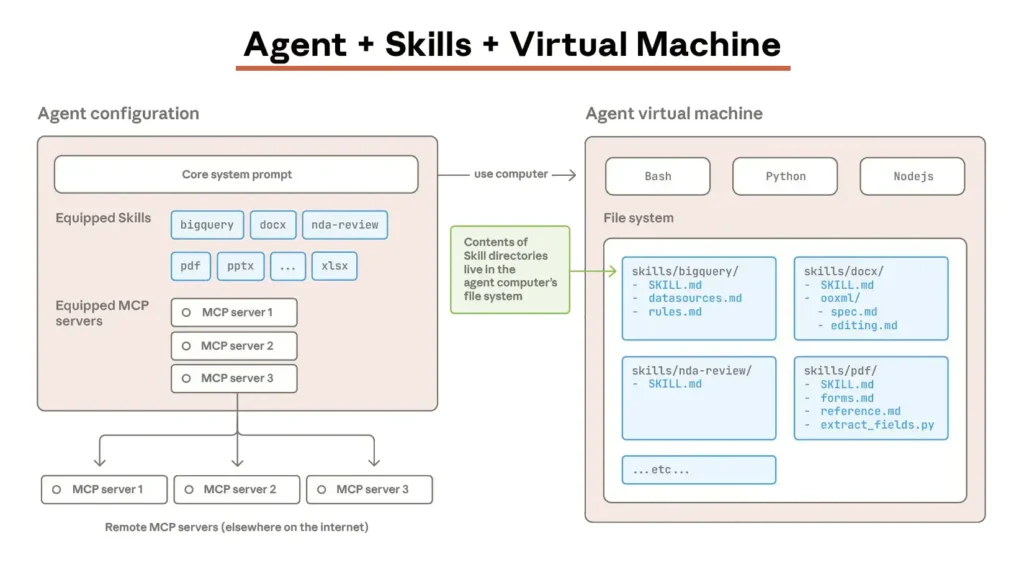
Agent Skills represent a fundamental rethinking of how we architect AI systems. Instead of treating the prompt as a monolithic instruction manual, Skills decompose agent capabilities into modular, filesystem-based packages that load on demand.
Think of it this way: a traditional prompt is like handing a new engineer a 5,000-page manual and expecting them to memorize it. Agent Skills are like giving them a well-organized file system where they know exactly which folder contains the information they need for each specific task.
The core architectural shift: The agent’s prompt becomes RAM (small, focused, active), while the filesystem becomes disk (large, modular, loaded only when needed). This isn’t just an optimization, it’s a different operating model.
How Does the Directory Structure Actually Work?
A Skill isn’t a black box. It’s a standard directory structure that lives in your version control system:
.claude/skills/financial-audit/
├── SKILL.md
├── scripts/
│ ├── fetch_transactions.py
│ ├── detect_anomalies.py
│ └── generate_summary.py
├── templates/
│ ├── audit_report.md
│ └── compliance_checklist.md
└── reference/
├── gaap_standards_2024.pdf
└── internal_policy_v3.mdEach component serves a specific purpose in the architecture:
- SKILL.md: The Orchestration Manifest: This is where you encode the business logic and workflow steps. It defines when this skill should activate, what inputs it expects, how it should coordinate the tools and references, and what outputs it should produce. It’s written in natural language but structured like an API specification; clear trigger conditions, explicit step sequences, and defined success criteria.
- Scripts Directory: Deterministic Code Execution: Instead of asking the LLM to “write a Python script to parse this transaction log,” you provide a tested, production-ready script. This shifts complex logic from probabilistic inference to deterministic compute. The agent becomes an orchestrator that knows when to call fetch_transactions.py and how to interpret its output, but it doesn’t reinvent the parsing logic on every execution.
- Templates: Enforcing Output Consistency: Rather than hoping the agent formats reports correctly through prompt instructions alone, you provide concrete examples. When generating an audit report, the agent loads audit_report.md as a template and fills in the specific findings. This dramatically improves reliability and makes outputs predictable enough to feed into downstream systems.
- Reference Materials: Load Only When Semantically Relevant: The 200-page GAAP standards document doesn’t sit in active context unless the agent is actually working on a GAAP-specific question. When it needs that information, it reads the relevant sections, extracts what’s needed, and the detailed content doesn’t pollute the context for subsequent tasks.
Where Do These Skills Actually Run?
One of the most powerful aspects of this architecture is deployment surface flexibility. The same skill package can run in fundamentally different contexts:
- In the IDE Through Claude Code: Developers use skills to automate local workflows. A “Pre-commit Review” skill might run linters, check for secrets, validate test coverage, and format the output as actionable fix-it items. The agent has access to the local filesystem, Git history, and development tools.
- In Production via the Claude API: Enterprise applications run skills in sandboxed cloud environments. A “Fraud Detection” skill might process transaction streams in real-time, calling internal APIs through MCP connectors, writing results to a database, and triggering alerts based on defined thresholds. This is headless automation where the skill runs without human intervention.
- In the Browser Through Claude.ai: End users can install skills into their personal Claude instance to customize behavior for their specific role. A legal team member might load a “Contract Review” skill that knows company-specific clause requirements and can work with uploaded documents.
This portability matters for governance. You define the skill once as code, version it in Git, and deploy it across surfaces with appropriate permissions and sandboxing per environment.
How Does Progressive Disclosure Optimize Context Usage?
The efficiency gains from Skills come from a three-level loading strategy that Anthropic calls progressive disclosure. Information loads only at the granularity required for the current task.
| Level | What Loads | When It Loads | Context Impact | Use Case |
| Discovery | Skill metadata (name, description, triggers) | On agent startup | ~50-100 tokens per skill | The agent knows this capability exists |
| Activation | Full SKILL.md instructions | When user query semantically matches | ~2K-5K tokens | The agent learns how to execute this capability |
| Execution | Scripts, templates, reference docs | During specific workflow steps | Streamed externally or cached | The agent accesses tools and knowledge as needed |
- Discovery Phase: At the discovery level, the agent loads only metadata. If you have 50 installed skills, that might be 5K tokens total; just enough for the agent to know what capabilities are available. When a user asks “Can you analyze this financial report?”, the agent scans metadata and identifies that the “Financial Audit” skill is relevant.
- Activation Phase: At the activation level, the agent loads the full SKILL.md for just that one skill. Now it has the detailed orchestration logic: fetch transactions first, then run anomaly detection, then cross-reference against compliance policies, then generate the report. This might add 3K tokens to active context; expensive, but justified because the agent is actively executing this workflow.
- Execution Phase: At the execution level, the agent runs scripts and reads references. But critically, this happens outside the inference context window where possible. When fetch_transactions.py executes, it returns a summary of findings, not the raw transaction log. When the agent needs to check a specific GAAP standard, it reads the relevant section and extracts the key requirements, rather than loading the entire 200-page document into context.
The Cumulative Impact: a query that might have required 100K tokens in a monolithic prompt system runs with 15K tokens in active context at any given time. The latency improvement is measurable, and the cost reduction is linear with token count.
What Engineering Patterns Enable Reliable Skill Execution?
Writing an effective skill requires thinking like a systems architect, not a prompt engineer. You’re designing an interface with defined inputs, outputs, and error modes. The best teams follow specific patterns:
1. Match Autonomy Levels to Task Risk Profiles
Not every task should give the model the same degree of freedom. The skill architecture lets you tune this explicitly.
- High-Risk Operations: Build Narrow Bridges: When a skill handles database migrations or financial transactions, you want minimal model autonomy. Provide exact scripts with strict guardrails. The SKILL.md might say: “Execute migration_script.py with the parameters from migration_config.json. Do not modify the script. If the script returns a non-zero exit code, halt and report the error.” The model is an operator following a precise procedure, not a creative problem-solver.
- Heuristic Tasks: Provide Open Fields: When a skill handles code review or technical writing, you want the model to apply judgment. The instructions are more like: “Review this code for common anti-patterns. Focus on: error handling, resource cleanup, security vulnerabilities, and performance concerns. Use your judgment to prioritize issues by severity.” You give methodology but trust the model’s reasoning.
- The Middle Ground: Guided Exploration: For tasks like data analysis, you might provide a framework: “Start with descriptive statistics. If you find anomalies, drill into those specific subsets. Use visualizations when patterns aren’t clear from numbers alone.” You’re providing structure without over-constraining the approach.
2. Use Deterministic Scripts for Complex Logic
The “Utility Script Rule” is simple: if a task requires complex, deterministic logic, don’t ask the LLM to generate that logic on the fly. Provide tested code.
The Anti-Pattern: A skill that prompts “You need to parse this CSV file. It has an unusual format with embedded line breaks in quoted fields and multiple header rows. Write Python code to handle this correctly.” Every time the agent runs this task, it might generate slightly different parsing logic. Sometimes it works. Sometimes it misses edge cases. This introduces variance into what should be a deterministic operation.
The Correct Pattern: Pre-Built Utilities
Provide scripts/parse_csv.py as a utility. The SKILL.md says: “Run parse_csv.py with the input file path. It returns a JSON array of records. If it returns exit code 1, the file format is invalid: report this to the user with the error message from stderr.”
The script is tested, handles edge cases reliably, and the agent becomes a coordinator rather than a code generator. This shift is critical for production reliability.
3. Implement Verification Loops for Multi-Step Workflows
Complex workflows benefit from a “Plan → Validate → Execute” pattern built into the skill instructions.
Consider a skill that generates database schema migrations. The wrong approach executes immediately and hopes for the best. The right approach builds verification into the workflow:
- Step 1: Plan: The agent generates migration_plan.json with the proposed schema changes.
- Step 2: Validate: The agent runs validate_migration.py which checks for breaking changes, constraint violations, and data loss risks.
- Step 3: Review: The validation script outputs either “safe to proceed” or a list of specific risks.
- Step 3: Execute: Only if validation passes does the agent run the actual migration script.
This pattern catches errors before they cause damage and makes the workflow transparent. You can inspect the plan, understand what validation ran, and audit the decision to proceed.
Stop Managing. Start Shipping.
Stop fixing “outsourced” spaghetti code.
Deploy an ISO 27001-certified engineering pod that hits your internal linting standards and security benchmarks from Day 1.
What Production Challenges Emerge at Scale?
Moving from prototype to production introduces operational complexity that many teams underestimate. The challenges aren’t theoretical: they’re what you hit at 100+ skills and thousands of agent invocations per day.
1. How Do You Handle Dependency Management and Runtime Isolation?
The problem surfaces quickly: Your “Data Science” skill needs pandas, scikit-learn, and matplotlib. Your “Finance” skill needs openpyxl and a specific version of numpy that conflicts with what the data science skill expects. Your “Security Scan” skill requires system-level tools like nmap that shouldn’t be available to other skills.
Why Naive Approaches Fail Immediately: Installing everything globally creates version conflicts and security risks. Asking the agent to install dependencies on-the-fly is slow and unreliable.
Treat Skills Like Microservices
Each skill declares dependencies explicitly, a requirements.txt for Python skills, package.json for Node.js, or a Dockerfile for system-level dependencies. In production, skills run in isolated environments:
- Docker containers provide full isolation with independent filesystems and dependency trees
- Firecracker VMs offer lightweight virtualization for environments requiring stronger security boundaries
- Virtual environments work for simpler cases where you just need dependency separation
The deployment pipeline handles this automatically: skill code commits to Git, CI builds the container or environment with declared dependencies, the production runtime loads the appropriate isolated environment when that skill activates.
This isn’t over-engineering. It’s the same isolation strategy you’d use for any production service, applied to agent capabilities.
2. How Do You Prevent Context Rot in Long-Running Conversations?
Progressive disclosure solves the initial loading problem, but it doesn’t automatically manage context lifecycle. In a 50-turn conversation where the agent uses multiple skills, the context window fills with residual state: old tool outputs, activated-but-no-longer-relevant instructions, intermediate reasoning chains.
Without lifecycle management, you recreate the monolithic prompt problem, just more slowly.
- Mark Completion Explicitly: When a skill finishes its workflow, the SKILL.md can instruct: “Once the audit report is generated and delivered, summarize the outcome in two sentences and remove all detailed transaction data from context.” The agent keeps the high-level result but forgets the intermediate details.
- Use Conversation Segmentation: For long sessions, implement a “context reset” pattern where completed tasks get archived to a session log, and the agent starts the next task with a clean context that includes only the session summary. This is analogous to how terminals handle screen buffer management.
- Implement Sliding Window Context: For very long sessions, keep only the N most recent turns in full detail, with older turns compressed into summaries. Anthropic’s extended context features make this feasible, but you need explicit logic to decide what stays verbose and what gets compressed.
The key insight: context management isn’t automatic. It’s a design decision you encode into skill instructions.
3. How Do You Handle Skill Discovery at Fleet Scale?
The progressive disclosure model assumes the agent can scan available skill metadata efficiently. At 10 skills, this is trivial. At 500 skills across an enterprise deployment, you’ve recreated the bloat problem.
Loading 500 skill descriptions into every agent startup prompt defeats the purpose of modular architecture.
The Solution: Semantic Skill Search
Instead of listing all skills in the base prompt, you give the agent a skill discovery tool. The architecture looks like this:
- The agent starts with a minimal prompt containing only core reasoning instructions
- When the user makes a request, the agent calls search_skills(query=”financial audit capabilities”)
- A vector search backend (using embeddings of skill descriptions) returns the 3-5 most relevant skills
- The agent loads only those skill manifests and proceeds with the task
This pattern scales to thousands of skills while keeping startup context minimal. It’s the same architecture pattern used for retrieval-augmented generation (RAG), applied to capability discovery.
Infrastructure Requirements
The implementation requires infrastructure: a skill registry, an embedding pipeline, and a search API. But for organizations deploying agent fleets at scale, this infrastructure pays for itself in reduced latency and context costs.
How Should Enterprise Teams Govern Agent Skills?
Deploying agents that execute code requires more than safe models. It requires safe capability frameworks with governance that scales across teams and risk profiles.
1. Implement Risk-Tiered Skill Classification
Not all skills carry the same risk. Effective governance starts with explicit categorization:
- Tier 1: Read-Only Intelligence: This tier includes skills that only consume information, document analysis, data visualization, report generation. These skills read from approved data sources but can’t modify state or trigger external actions. Approval workflows can be lightweight: code review and basic testing.
- Tier 2: External Integration: This tier includes skills that call APIs, integrate with third-party services through MCP connectors, or query internal systems. They can retrieve data and trigger workflows but operate within defined API boundaries. These require security review: credential management, rate limiting, API permission scopes.
- Tier 3: System Modification: This tier includes skills that write to databases, execute shell commands, modify infrastructure, or handle financial transactions. These are high-consequence operations. They require: security review, change management approval, automated testing in staging environments, and deployment controls like canary rollouts.
Determining Approval Requirements: The tier determines the approval chain, testing requirements, and production deployment controls. A Tier 1 skill might deploy after code review. A Tier 3 skill might require security sign-off, QA validation, and phased rollout.
2. Treat Skills as Infrastructure-as-Code
The most successful enterprise deployments treat skills like any other software artifact:
- Source Control Is Mandatory: Every skill lives in Git with full version history. You can see who changed what, when, and why. You can roll back to previous versions if a change introduces regressions.
- CI/CD Pipelines Automate Quality Gates: On commit, automated tests run: syntax validation, security scans, permission checks, integration tests against sandbox environments. Skills don’t reach production without passing gates.
- Versioning Prevents Behavior Drift: Production agents pin to specific skill versions by Git hash or semantic version tag. When you update a skill, you can deploy the change gradually: staging first, then 10% of production traffic, then full rollout. If anything breaks, rollback is one command.
- Observability Is Built-In: Skills emit structured logs: which skill activated, what inputs it received, what scripts it ran, what outputs it produced. This makes debugging production issues tractable and supports audit requirements.
This isn’t just good practice; it’s the minimum viable governance for systems that execute code autonomously.
Why Should CTOs Care About Modular Agent Architecture?
For engineering leaders, the shift to modular skills isn’t primarily a technical optimization. It’s a strategic hedge against the two biggest risks in AI adoption: escalating costs and vendor lock-in.
1. Economic Scalability: Making High-Volume AI Viable
The unit economics of prompt stuffing make continuous, high-frequency agent usage prohibitively expensive. If every customer service interaction loads 100K tokens of context, your inference costs scale linearly with conversation volume. This creates a ceiling on how much AI you can deploy.
Modular architecture changes the cost curve. By loading only relevant capabilities on-demand, you reduce the average context size per interaction from 100K tokens to 10K-20K. That’s a 5-10x reduction in inference costs for the same functionality.
This isn’t theoretical. We’ve seen production deployments reduce their monthly API bills by 60-70% by migrating from monolithic prompts to modular skills, while maintaining or improving task success rates. That’s the difference between “AI is an interesting experiment” and “AI is a core part of our product.”
The economic impact compounds: lower costs enable higher usage volumes, which enables more ambitious automation workflows, which drives ROI that justifies further investment.
2. Architectural Portability: Avoiding Model Lock-In
The AI model landscape is evolving rapidly. Today’s state-of-the-art will be surpassed by next quarter’s release. Providers change pricing, capabilities, and availability. Betting your entire architecture on prompt patterns optimized for one specific model is risky.
Modular skills create a portable abstraction layer. Your business logic (the orchestration steps, the domain knowledge, the workflow patterns) lives in structured files and tested scripts. The skill manifest is model-agnostic. The actual inference work the model does is relatively generic: understanding which skill to activate, following the instructions in SKILL.md, coordinating tool calls.
This means you can migrate between models without rewriting your entire agent system. If Claude pricing changes, you can evaluate whether GPT-4 or the next Gemini release can execute the same skills with acceptable quality. If a new model offers better reasoning for code tasks, you can route your “Code Review” skill to that model while keeping other skills on Claude.
The portability extends beyond models to deployment surfaces. The same skill that runs in Claude Code for developers can deploy through the API for production automation, or load in Claude.ai for end users, with only environment-specific configuration changes.
3. Strategic Ownership: Skills as Company Assets
Perhaps most importantly, modular skills shift where your AI value lives. With prompt stuffing, your competitive differentiation is trapped in opaque prompt text that’s hard to version, test, or audit. With skills, your differentiation becomes a versioned codebase.
Your “Financial Audit” skill encodes your company’s specific compliance requirements, risk thresholds, and reporting standards. That’s proprietary business logic, captured in a form you control, that can be tested, improved, and governed like any software system.
This changes the ownership model. You’re not just buying API credits; you’re building reusable, improvable agent capabilities that become more valuable over time as you refine them based on production usage.
What Does the Transition Path Look Like?
For teams currently running production agents on monolithic prompts, the migration to modular skills isn’t a rip-and-replace. It’s an incremental refactoring that delivers value at each step.
- Start with Your Highest-Cost, Highest-Volume Workflow
Identify the agent task that consumes the most context tokens and runs most frequently. Extract that capability into a dedicated skill. Measure the context reduction and cost savings. This proves the ROI and builds team experience. - Establish the Infrastructure Foundations Early
Set up the skill registry, the directory structure conventions, the CI/CD pipeline, and the deployment automation before you have 50 skills. The patterns that work for skill #5 will break at skill #50 if you don’t build proper tooling. - Prioritize Skills That Reduce Operational Toil
The highest-leverage skills aren’t necessarily the most sophisticated; they’re the ones that automate repetitive tasks that currently require human intervention. Document generation, data validation, routine analysis tasks. These skills deliver immediate productivity gains while you build toward more ambitious automation. - Build Governance Practices Alongside Technical Capabilities
Don’t wait until you have a security incident to implement review processes and tiered approvals. Start with lightweight governance for early skills, then formalize it as the risk profile increases. - Treat This as a Platform Initiative
The teams seeing the most success treat this as a platform initiative, not a series of one-off agent projects. They’re building the capability to deploy agent skills at scale, with the same rigor they’d apply to any production infrastructure.
Conclusion
The shift from monolithic prompts to modular agent architecture represents a maturation of AI engineering. We’re moving from “throw everything in the prompt and hope the model figures it out” to “design explicit interfaces, version business logic, and govern capabilities systematically.”
This isn’t just about efficiency or cost reduction, though those benefits are real. It’s about making AI systems that can scale to production workloads, that can be governed with the rigor enterprise requires, and that remain maintainable as they grow in complexity.
The teams that make this transition now are building the foundation for AI systems that evolve and improve over time, rather than accumulate technical debt and eventually collapse under their own complexity.
Stop Managing. Start Shipping.
Stop fixing “outsourced” spaghetti code.
Deploy an ISO 27001-certified engineering pod that hits your internal linting standards and security benchmarks from Day 1.