TL;DR
- Most offshore failures are not talent failures. They are operating-system failures.
- Hiring engineers offshore is not the same as building an offshore capability.
- Seven operating layers must exist for a remote team to function as a real capability center.
- Without documentation, retention infrastructure, and delivery governance, context bleeds out faster than the team can accumulate it.
- Security and compliance are not negotiable features. They are the foundation. For US companies in healthcare or fintech, they must exist before day one.
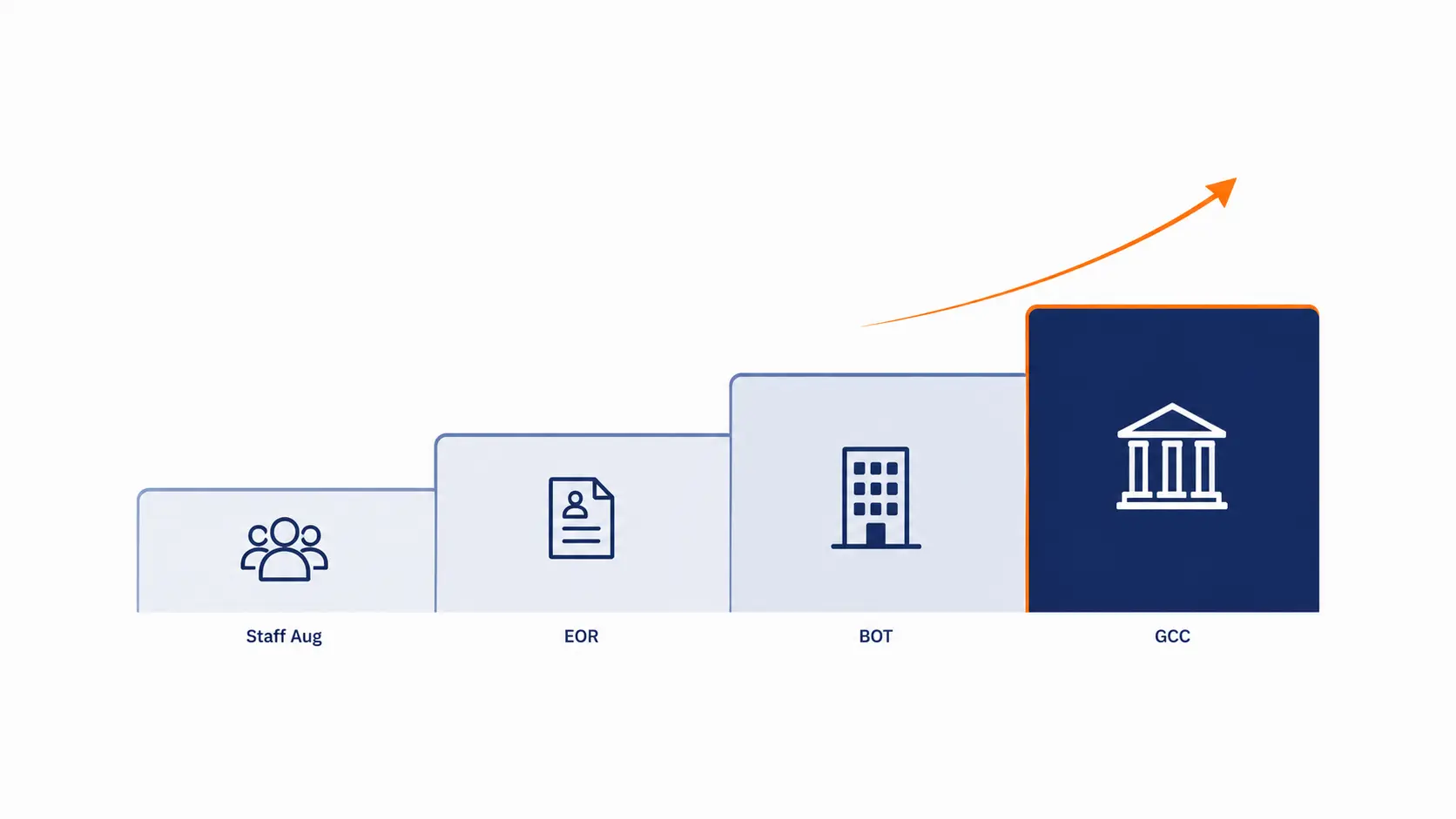
- What you pay for in a BOT engagement is not just the team. It is the operating system around the team.
- The right partner evaluation checklist tells you in advance whether a transfer will actually succeed.
The Mistake That Costs CTOs 12 Months
Here is the pattern that repeats across offshore engagements that fail.
A founder or CTO identifies a talent need. They find a vendor or recruiter. They hire eight to twelve engineers in India, Nepal, or LATAM. They set up Slack channels, add the engineers to the sprint board, and call it a team.
Six months later, the symptoms appear. Delivery is slow. Context has to be re-explained constantly. Engineers ask the same questions the previous cohort asked. Code quality is inconsistent. The CTO is spending four hours a day on offshore sync calls that should take forty minutes. A senior engineer resigns, and it turns out no one else understands the system they owned.
The founder’s diagnosis: the talent was not good enough.
The actual diagnosis: there was no operating system around the talent.
This distinction matters. Talent and an operating system are not the same thing. You can have excellent engineers and still produce offshore chaos if the infrastructure around them is absent. The operating system is what converts a group of capable individuals into a capability that compounds over time.
The founders who succeed with offshore do not just hire better engineers. They build the structure that makes engineers better.
Research Finding: The difference between offshore chaos and offshore capability is not the talent. It is the operating system around the talent. Founders who struggle with offshore almost always made the same mistake: they hired engineers and called it a team. They got capacity but not capability.
Why Staff Augmentation Creates Management Drag
Before examining what the operating system requires, it helps to understand what happens without it.
Staff augmentation is the default first move for most offshore hiring. You bring in contractors through a vendor. Your internal team directs their work. The vendor handles payroll and local administration. It is fast and flexible.
The structural problem is this: staff augmentation puts all operating weight on your internal team. Every context transfer, every architectural decision, every onboarding cycle, every quality review lands on your engineers and your CTO. The augmented engineers are capable, but they are not embedded. They do not own outcomes. They complete tasks.
Over time, this creates management drag. Your CTO shifts from strategic architecture to daily delivery oversight. Senior engineers spend 30% of their time bringing contractors up to speed. Coordination meetings multiply. The capacity you added creates overhead that partially offsets the capacity.
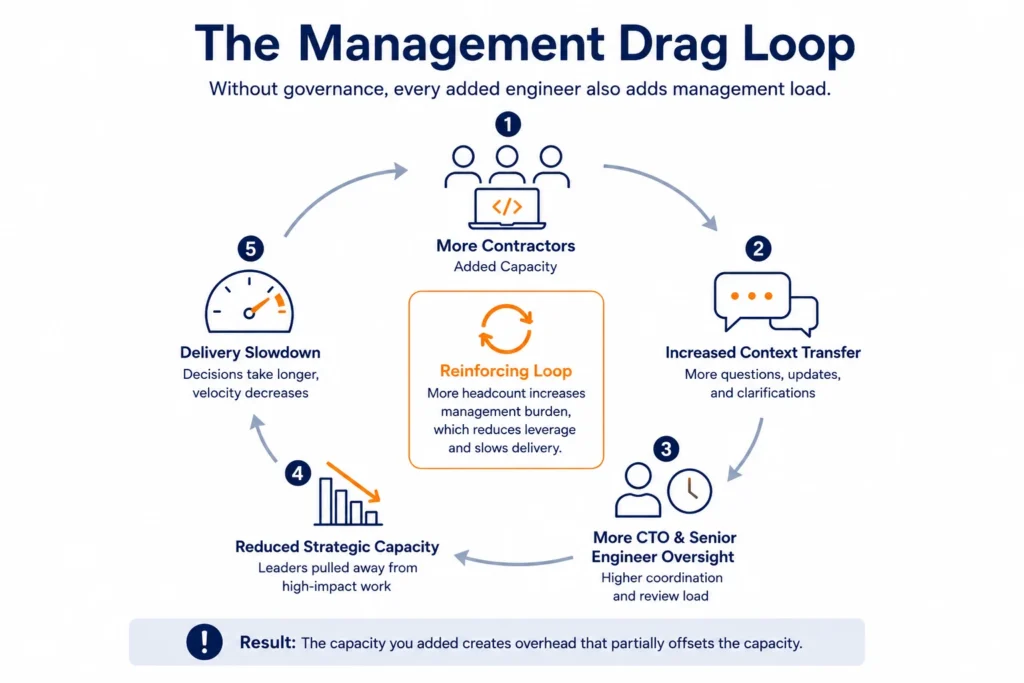
The scale problem compounds this. Research on US hiring timelines shows that replacing a single senior engineer takes 60 to 90 days and costs the organization four to eight weeks of team velocity during onboarding. For distributed teams with high contractor rotation, this cost runs continuously.
When augmented engineers turn over, which they do, they take institutional knowledge with them. Organizations with annual turnover above 20% lose an average of 42% of project-specific knowledge. That knowledge does not exist in documentation, because no one built a documentation system. It existed in individuals.
The solution is not to hire better contractors. The solution is to build the operating layer that prevents knowledge from being individual in the first place.
| Management Drag Indicator | What It Signals |
|---|---|
| CTO on daily offshore sync calls over 30 minutes | No delivery governance layer exists |
| Same architectural questions asked by new engineers | No documentation or onboarding system |
| Sprint velocity drops after a contractor leaves | Institutional knowledge was individual, not systemic |
| Offshore engineers reactive rather than proactive | No product context ownership; ticket-mentality is structural |
| Security incidents or access control gaps | No security governance layer |
The Seven Operating Layers a Real Offshore Capability Needs
An offshore capability is not just engineers at desks. It is a system of interdependent layers that enable those engineers to produce, retain, and eventually transfer value. Each layer below represents a distinct operating function. Remove any one of them and you get a specific category of failure.
Layer 1: Talent Acquisition and Assessment
Most offshore hiring is reactive. A role opens, a recruiter sources candidates, an interview happens. The bar varies by urgency.
A real operating layer replaces this with a proactive system. It includes an established employer brand in the local market, a warm candidate database built over time, multi-stage technical assessment, cultural alignment screening, and client evaluation rounds before final hire.
The difference in output is significant. Reactive sourcing fills seats. Proactive systems build pipelines of engineers who join because they want to work on your product, not because it was the fastest offer.
For a BOT engagement, this means the partner’s hiring engine needs to exist before you arrive. You should not be the first company they have ever sourced for. Ask how many engineers are in their active candidate database and what their average time-to-hire looks like for senior roles.
Layer 2: Onboarding and Domain Training
Generic onboarding trains engineers on tools and processes. Domain onboarding trains them on the product, the industry, the compliance context, and the business logic behind what they are building.
The gap between these two is where most offshore quality problems originate. An engineer who understands the codebase but does not understand why the product works the way it does will write technically correct code that creates product problems.
For regulated verticals, this layer is critical before day one. Healthcare companies handling PHI need engineers who understand HIPAA data handling protocols, not engineers who learn about them during a compliance audit. Fintech companies need engineers who understand data sovereignty requirements, not engineers who handle those issues reactively.
The operating layer here includes: contracts and orientation, domain-specific training, product context immersion, compliance briefings, and cultural alignment programming. For a team like the one TechKraft built for Abacus Insights, this meant all engineers received training in US payer data structures, CMS compliance rules, HIPAA, and PHI handling before they touched production systems.
Layer 3: HR, Payroll, and Retention
This is the layer most founders underestimate most severely.
A functioning HR layer is not just payroll processing. It includes statutory fund registration (PF, SSF, or equivalent), benefits administration, performance review cycles, proactive retention programming, and the kind of ongoing employee relationship management that keeps engineers from leaving after 18 months.
Retention is not a soft metric in a BOT or GCC context. It is the mechanism that makes the transfer valuable. If your offshore team churns every 18 months, there is nothing to transfer. The institutional knowledge, the product context, the architectural understanding, and the culture all live in the people. When the people leave, those assets leave with them.
TechKraft’s 8% attrition rate against an industry average of 25% or higher is not incidental. It reflects an HR operating layer that actively invests in retention, not one that processes paperwork and responds to resignations.
Layer 4: Delivery Governance and Reporting
Delivery governance is the operational connective tissue between your offshore team and your engineering roadmap.
Without it, offshore teams drift. Priorities shift locally without HQ visibility. Sprint velocity is hard to measure cross-timezone. Performance accountability becomes ambiguous. Engineers receive conflicting direction from local managers and remote product owners.
A real delivery governance layer includes:
- A delivery manager with clear accountability for team output, not just team administration
- Sprint integration with your existing agile workflow and ceremonies
- SLA definitions with documented escalation paths
- Regular performance reporting with metrics tied to product outcomes, not just task completion
- Structured feedback loops between offshore leadership and your engineering directors
This layer is what allows a CTO to reduce offshore sync time from four hours a day to forty minutes. The governance handles the operational coordination. The CTO handles strategy.
Layer 5: Security, Compliance, and Access Control
For most US founders, this is the layer with the highest non-compliance consequence.
Security and compliance are not features you add later. They are the foundation you build on before the first engineer accesses your systems. In a BOT engagement, this means the partner’s security posture must meet your requirements from day one, not after a compliance review six months into the engagement.
A functioning security layer covers six distinct planes:
- Operational security covers IS policies, secure onboarding and offboarding, risk assessment frameworks, and training. This is the governance baseline that everything else depends on.
- Physical security covers 24/7 CCTV monitoring, biometric access controls, redundant power systems, and physical barriers that prevent unauthorized facility access.
- Identity and access management (IAM) covers the least-privilege principle, role-based access control (RBAC), multi-factor authentication (MFA), and regular access reviews. No engineer should have access to systems they do not need for their specific role.
- Endpoint security covers device protection, endpoint monitoring, remote wipe capability, and anti-virus management. Every device that accesses your systems is a potential exposure point.
- Network security covers VLAN segregation, real-time traffic monitoring, VPN enforcement for external access, and network segmentation that isolates sensitive environments from general-use infrastructure.
- Data security covers encryption at rest and in transit, backup and recovery systems, off-site backup protocols, and data retention policies that meet your regulatory requirements.
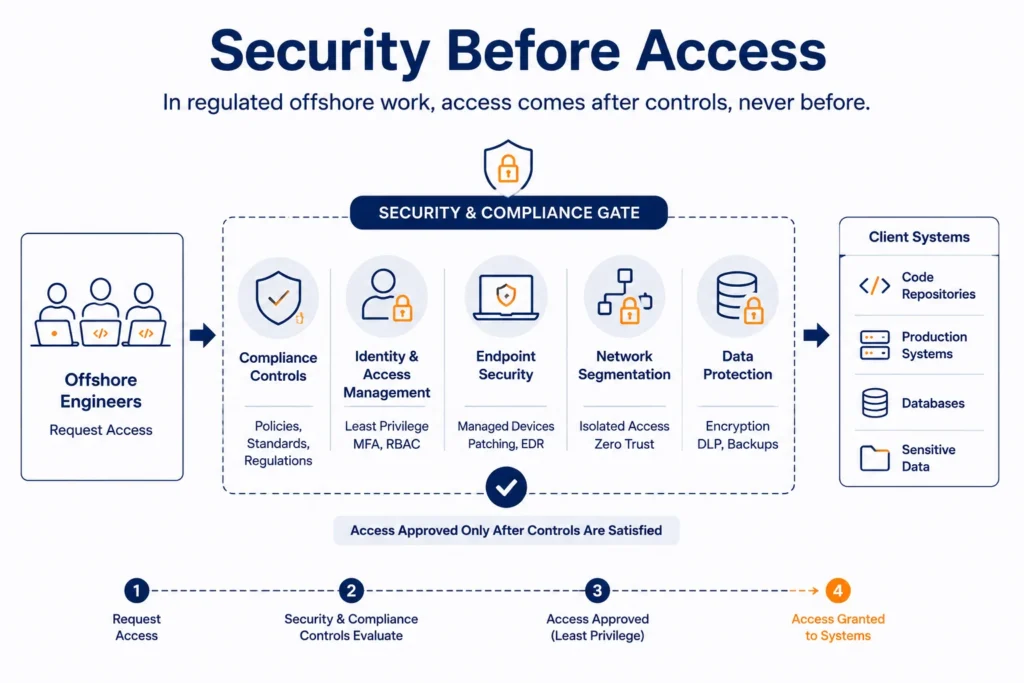
For companies handling PHI, PII, or sensitive financial data, two additional requirements apply. First, ISO 27001:2022 certification and HIPAA compliance from the partner are non-negotiable, not aspirational. Second, Clean Room protocols: physically segmented work areas with strict device usage policies and no external data transmission capability. This is the standard TechKraft operates to for clients like Abacus Insights.
| Security Layer | What It Covers | Key Standards |
|---|---|---|
| Operational | IS policies, risk assessment, staff training | ISO 27001:2022 governance framework |
| Physical | CCTV, biometric access, power redundancy | Physical security controls |
| IAM | RBAC, MFA, least privilege, access reviews | Zero-trust access principles |
| Endpoint | Device protection, monitoring, remote wipe | Endpoint security protocols |
| Network | VLAN, real-time monitoring, VPN, segmentation | NIST network security controls |
| Data | Encryption at rest and in transit, backup, recovery | AES-256 encryption, HIPAA data standards |
Research Finding: For US tech founders in healthcare, fintech, or any regulated vertical, security and compliance are not table stakes you negotiate. They are the foundation you build on. Every engagement includes NDAs, contractual IP assignment, secure repository access, and role-based access control from day one. Your code, your data, your models: all stay yours throughout the engagement and transfer cleanly at handoff.
Layer 6: Documentation and Knowledge Management
Documentation is how institutional knowledge survives personnel change.
Without it, every engineer departure is a partial system failure. The engineer who understood why a critical API was built a particular way is gone. The engineer who knew the edge case behavior in the data pipeline is gone. The team inherits a system it does not fully understand and starts making decisions that create technical debt because the context is missing.
A real documentation layer includes:
- Standard operating procedures (SOPs) for all recurring operational and delivery processes
- Confluence-based or equivalent knowledge bases with architecture decision records
- Onboarding manuals that new engineers can use to reach productivity without requiring senior engineers to repeat themselves
- Knowledge elicitation sessions that extract context from individuals and systematize it into shared documentation
- Code-level documentation standards enforced through code review, not aspirationally
This layer is what makes a transfer valuable rather than nominal. When ownership transfers from a BOT partner to a client, what actually transfers is not just the people. It is the documented context, the architectural rationale, the compliance playbooks, and the operational runbooks that allow a new management layer to run the team without rebuilding institutional knowledge from scratch.
Without documentation, you do not transfer a capability. You transfer a headcount.
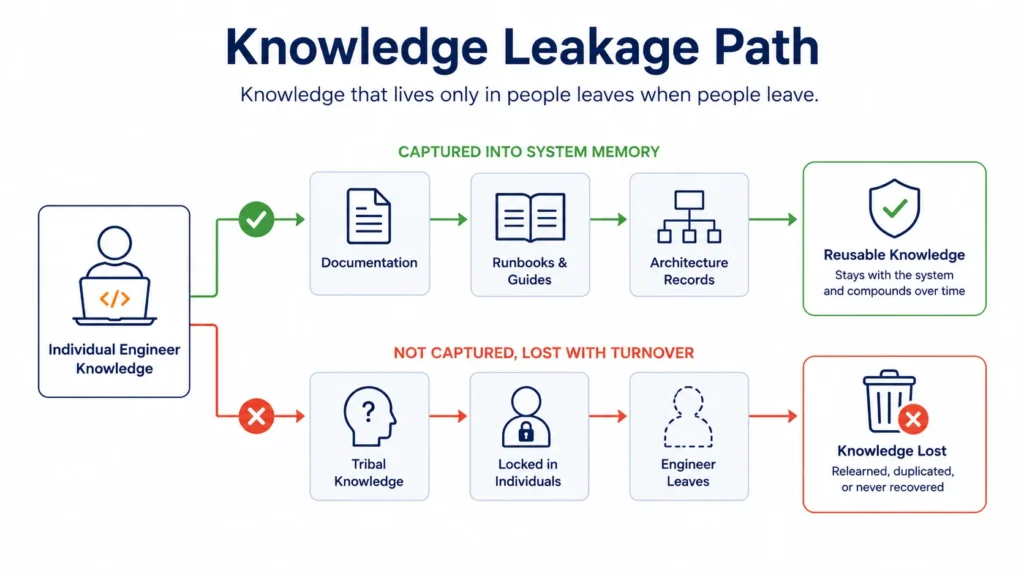
Layer 7: Transfer Readiness Planning
Transfer readiness is not a phase you start planning when the transfer is six months away. It is a discipline you build into the operating model from day one.
This layer includes:
- Shadow leadership programs that introduce client-designated leaders 6 to 12 months before transfer, working alongside partner management before officially assuming authority
- Governance transition design that maps the shift from partner-led oversight to client-led oversight, including escalation paths, vendor relationship management, and statutory compliance ownership
- Knowledge elicitation protocols that systematically extract context from partner-managed systems and individuals before the handover
- Transfer trigger documentation that defines the specific operational maturity thresholds required before transfer can proceed, not arbitrary calendar dates
The most common failure mode in BOT transfers is triggering the handover on a fixed date regardless of operational readiness. A transfer should be triggered by verified milestones, not contract anniversaries. These include sustained SLA attainment over multiple consecutive quarters, documentation coverage of all critical processes, and demonstrated local leadership independence from the partner’s management layer.
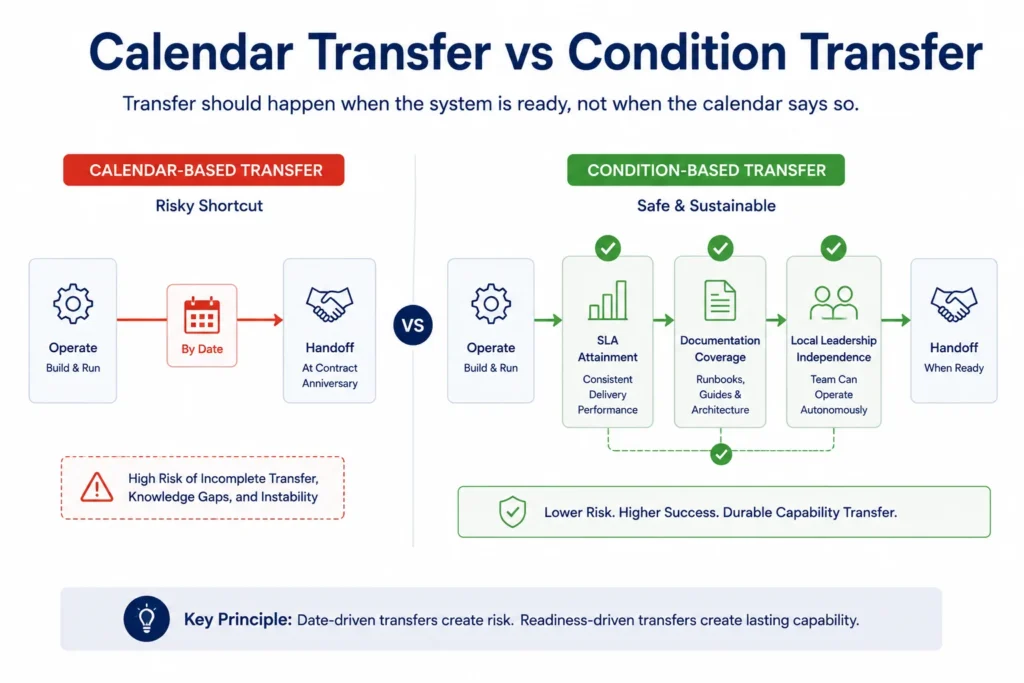
Research Finding: Condition-based transfer triggers prevent post-transfer chaos. SLA attainment for six consecutive months, full documentation of critical processes, and demonstrated local leadership independence are the three indicators that define genuine transfer readiness. Calendar-based transfers ignore these entirely.
What You Actually Pay for in a BOT Engagement
Understanding BOT pricing requires understanding what you are buying. It is not just the team’s compensation.
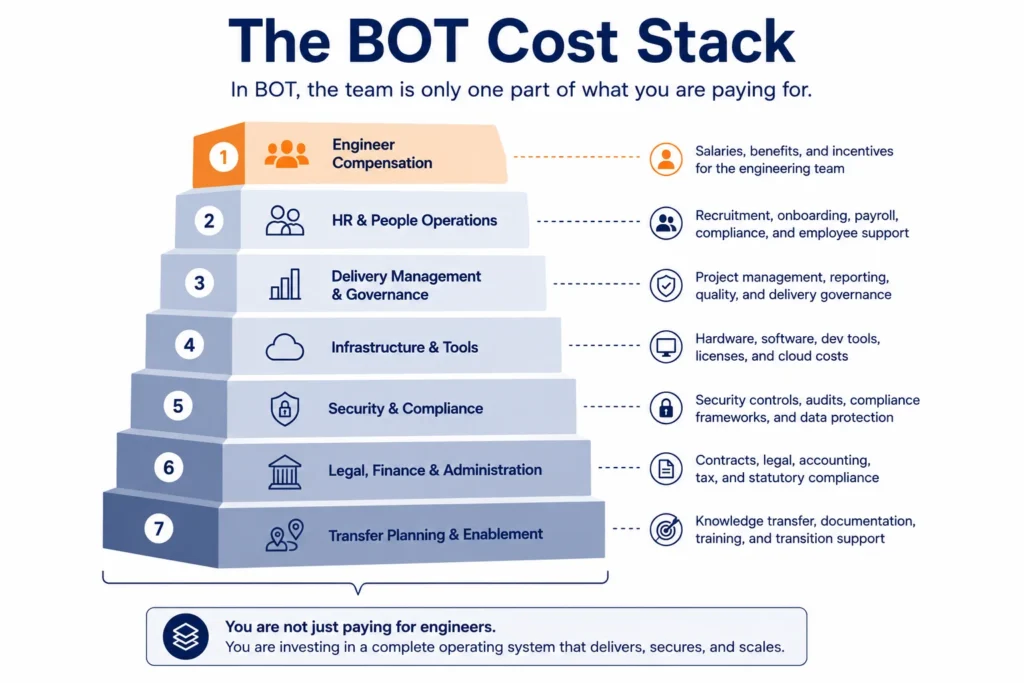
Resource-based BOT pricing for GCC builds includes:
- Monthly resource cost, fully loaded: this covers salary, benefits, statutory fund contributions (PF/SSF equivalent), and recruitment cost amortized over tenure
- Managed operations layer: this covers the delivery manager, HR business partner, and performance management infrastructure
- Infrastructure and workplace: physical office, IT provisioning, security tooling, and workplace administration
- Compliance and administrative support: statutory filings, legal support, payroll processing, and audit readiness
- Transfer planning and execution: shadow leadership programs, governance transition design, and knowledge elicitation
What you avoid by not building directly:
- Entity registration costs: $5K to $15K in filings alone before a single hire
- Office lease negotiation and fit-out: 12 to 18 months to occupancy in most Tier-1 markets
- HR system setup: policies, payroll software, statutory frameworks built from zero
- Compliance audit costs: ISO certification, HIPAA alignment, and security architecture without prior expertise
- Wrong leadership hires: the single most catastrophic direct GCC failure mode, and the hardest to reverse
- Regulatory surprises: every jurisdiction produces at least one, and the first one usually comes after you have already committed capital
| Cost Component | BOT Engagement | Direct GCC Build |
|---|---|---|
| Upfront CapEx | Near zero (absorbed by partner) | $500K to $1.25M before first hire |
| Time to first productive engineer | 4 to 8 weeks | 9 to 18 months |
| HR infrastructure setup | Included in managed operations | Built from scratch |
| Security architecture | Pre-built to ISO 27001, HIPAA | Designed and certified independently |
| Leadership hire risk | Shared with partner | Fully owned by client |
| Transfer planning | Built into operating model | Non-existent until you decide you need it |
The economics shift at scale. Once a transfer completes, the partner’s management margin disappears. You pay direct operating costs only. Research on BOT-to-GCC transitions suggests the total cost of ownership over a 36-month horizon under a managed BOT arrangement substantially outperforms the perpetual costs of traditional outsourcing, with operating cost reductions of 15% to 35% post-transfer compared to ongoing vendor relationships.
What to Ask a BOT Partner Before You Sign
The partner evaluation conversation is where most selection errors happen. Founders ask about team size and certifications. They should be asking about transfer track record and retention mechanics.
| Evaluation Dimension | What to Look For | Red Flag |
|---|---|---|
| Engineering breadth | Can they staff product, data, cloud, security, and QA? | Narrow capability in one or two domains only |
| Business function support | Do they provide HR, finance, operations, IT, and compliance? | Engineering-only model with outsourced admin |
| Local hiring engine | Active candidate database of 20,000+ and proven sourcing track record | Only reactive sourcing; no warm pipeline |
| Compliance certifications | ISO 27001:2022 certified, HIPAA compliant, audit-ready | Aspirational compliance; in progress certifications |
| Security architecture | Multi-layer model, Clean Room capability for PHI/PII, audit-ready access controls | Blanket security claims without architecture documentation |
| Actual attrition rate | Single-digit attrition with evidence, compared against industry average | Market-average attrition (25%+) with no retention differentiation |
| Transfer track record | Completed ODC-to-BOT transitions with named clients and verifiable proof | No completed transfers; perpetual operate-phase clients only |
| Shadow leadership programs | Structured program 6 to 12 months pre-transfer | No transition plan until transfer is imminent |
| Onboarding pathway | Documented, phased process from contract to transfer readiness | Sales pitch only; no documented methodology |
| Flexibility on timing | You can stay in Operate phase or exit if needed | Contractual pressure to transfer on fixed date regardless of readiness |
One question is worth adding to every partner evaluation: “How many of your clients have completed a full transfer, and can I speak with one of them?”
A partner who is contractually rewarded only for operational continuity may be subtly incentivized to maintain your dependency. The evaluation framework above is designed to identify that incentive misalignment before you sign, not after you have been in the Operate phase for 24 months.
A Practical Onboarding Pathway
What a governed, documented onboarding pathway looks like when all seven operating layers are in place:
Phase 1: Contract and Compliance: NDAs executed, IP assignment framework documented, security access controls defined, and HIPAA or ISO audit readiness confirmed before any engineer accesses client systems.
Phase 2: Discovery and Alignment: Partner embeds with client to understand product architecture, domain context, delivery cadence, and technical standards. Hiring plan is co-developed. Not a generic team design, but one built for this specific product and roadmap.
Phase 3: Team Setup: Multi-stage sourcing and assessment. Cultural alignment screening alongside technical evaluation. Engineers hired under client employer brand where applicable. Physical infrastructure and security configuration completed.
Phase 4: Operational Kickoff: First sprint integration. Delivery governance SLAs agreed. Reporting cadence established. Domain training for all engineers completed before production system access.
Phase 5: Engagement and Tracking: Regular performance reviews against agreed SLAs. Delivery manager accountability active. Documentation standards enforced. Retention programs running. No context living exclusively in individuals.
Phase 6: Review and Optimization: Quarterly governance reviews. Attrition tracking vs. target. Knowledge base completeness audits. Transfer readiness indicators tracked as leading metrics, not lagging ones.
Phase 7: Transfer Readiness: Shadow leadership program active. Governance transition designed. Knowledge elicitation completed. SLA attainment sustained over six consecutive months. Transfer triggered by conditions, not calendar.
Every phase is governed. Every phase is documented. Context does not disappear when people change, because the system holds it, not the individuals.
The Governance Test
Before you make your next offshore hiring decision, run this diagnostic. Ask whether your current setup has all seven operating layers.
If the answer is no, you do not have an offshore capability. You have offshore capacity. The distinction is not semantic. Capacity rents. Capability compounds.
A team without delivery governance will drift from your roadmap within 90 days. A team without documentation will bleed context every time someone leaves. A team without retention infrastructure will give you average attrition, which means 25% of your institutional knowledge walks out the door every year.
The operating system is not overhead. It is the product. What you are building toward is not 20 engineers in Kathmandu writing code. What you are building toward is a stable, documented, high-retention offshore operation that you eventually own. The operating system is what makes that transfer worth executing.

The BOT Path to GCC: A Founder’s Guide
Get the complete founder’s playbook on
Build-Operate-Transfer.
Includes:
BOT framework, readiness checklist & case study