🎧 Listen to the Podcast Version
Prefer listening over reading? This is a podcast-style discussion generated from the article — not a text-to-speech narration.
⏱ ~ 21 min listen • Best for multitasking
TL;DR
- Every undocumented engineering decision creates a future management cost. Most teams never measure this.
- The Artifact-First Operating System replaces informal trust with mechanical enforcement.
- Five artifacts (RFC/ADR, Binary DoD, CI Traceability, Runbooks, Docs-as-Code) cover 90% of handoff risk.
- Teams using artifact-driven workflows consistently reduce rework by 40-60% and cut onboarding time in half.
- Techkraft enforces this as structural policy, not optional practice.
The Tax You’re Already Paying
Most CTOs underestimate one specific cost. It is not vendor fees. It is not cloud spend.
It is the management tax: the invisible overhead created every time a decision lives in someone’s head instead of a documented artifact.
The pattern looks like this:
- A senior engineer makes a key architectural call during a Slack thread.
- The thread is not captured in any formal record.
- Three weeks later, an offshore team member blocks on the same decision.
- A senior engineer is pulled out of deep work to re-explain the context.
- The work is delivered late. The spec changes. Rework begins.
This is not a people problem. It is a systems problem. And it compounds at scale.
According to the DORA State of DevOps Report, elite engineering teams deploy 973x more frequently than low performers. The single strongest differentiator is not headcount. It is documentation infrastructure and CI/CD discipline.
The management tax does not show up in a single sprint. It accumulates silently, in blocked tickets, in onboarding delays, and in production incidents that lack traceable context.
The fix is not better communication. The fix is an operating system built on artifacts.
The Thesis
Here is the core model in one sentence:
“If it isn’t an artifact, it doesn’t exist.”
This is not a metaphor. It is an operational constraint.
If a decision was made verbally, it did not happen in any recoverable sense. If a ticket lacks acceptance criteria, it cannot be tested. If a runbook was never written, the next incident will cost double. Every gap between a decision and its documented record is a future liability on your engineering balance sheet.
The Artifact-First Operating System treats documentation as mechanical enforcement, not cultural aspiration.
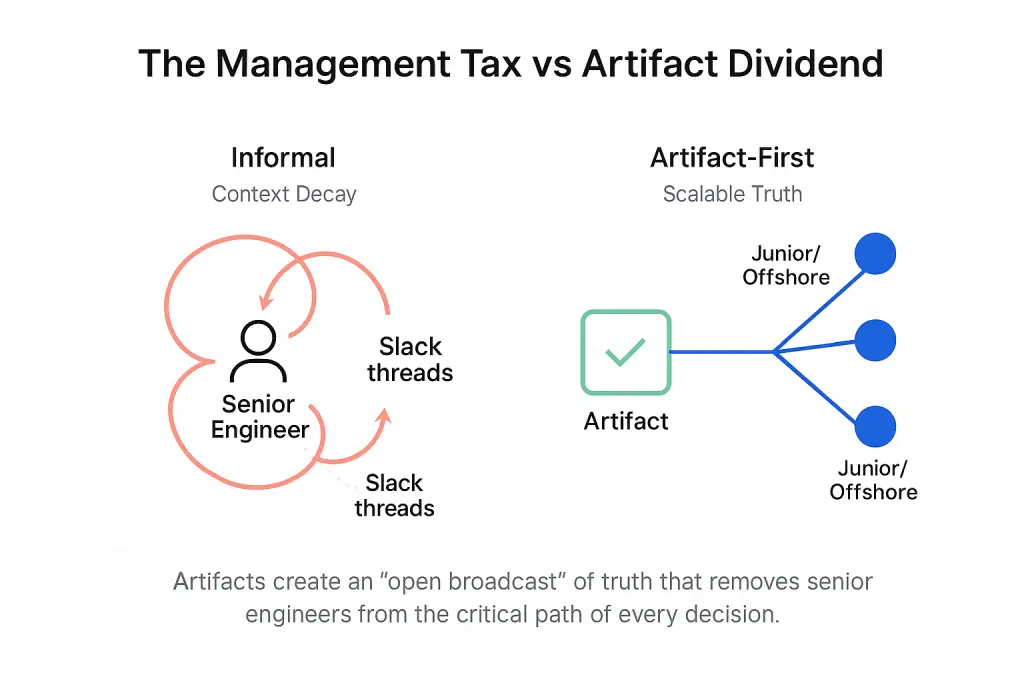
What the Artifact-First OS Actually Means
This is not a documentation framework. It is a production system with defined inputs and outputs.
The five operating principles are:
- No decision is final until it is version-controlled. Verbal alignment has no audit trail. RFCs and ADRs create one.
- Every ticket ships with binary acceptance criteria. Pass or fail. No ambiguous “done.”
- All deployments are traceable to a commit. Any engineer can answer: “What shipped, when, and why?”
- Every service has a runbook. The author’s presence is never required for incident response.
- Documentation lives in the repository, not a wiki. Code reviews gate spec changes just as they gate code changes.
These are not suggestions for high-performing teams. They are table stakes for distributed engineering at any meaningful scale.
Stop Managing. Start Shipping.
Stop fixing “outsourced” spaghetti code.
Deploy an ISO 27001-certified engineering pod that hits your internal linting standards and security benchmarks from Day 1.
The Five Non-Negotiable Artifacts
1. RFCs and Architecture Decision Records
An RFC (Request for Comments) captures the thinking before work begins. An ADR (Architecture Decision Record) captures the decision after alignment is reached. Together, they create a permanent record of why a system was built the way it was.
Without them, your architecture becomes archaeology. Senior engineers spend hours re-excavating old decisions instead of making new ones.
| Document Type | When It’s Created | Primary Purpose | Audience |
|---|---|---|---|
| RFC | Before complex work begins | Gather input, surface risks | Full team plus stakeholders |
| ADR | After a decision is finalized | Record the rationale permanently | Future engineers |
| Ticket / Issue | At task creation | Define scope and acceptance criteria | Assignee and reviewer |
The rule: No RFC means no start. No ADR means no merge.
2. Binary Definition of Done
Ambiguity in acceptance criteria is one of the highest-leverage failure points in distributed engineering.
“Done” cannot mean “I think it works.” It must mean a specific set of verifiable conditions passed.
A binary DoD requires:
- Explicit pass/fail test coverage for every acceptance criterion, written before development starts.
- Documented edge cases and failure modes, not just happy paths.
- No merge without reviewer sign-off on the complete DoD checklist.
- QA and stakeholder sign-off criteria defined at ticket creation, not at review time.
Pro-Tip: Teams that define acceptance criteria at ticket creation reduce rework by an average of 25-30%. Waiting until sprint review to clarify “done” is where most distributed teams lose their delivery margin.
The binary DoD removes subjectivity from the definition of “complete.” It makes handoffs between engineers, time zones, and pods structurally frictionless.
3. CI Traceability
Every production deployment must be traceable to four things:
- The commit that introduced the change.
- The ticket or RFC that authorized the change.
- The engineer who approved the merge.
- The automated test results at the time of merge.
This is not optional for distributed teams. Without it, production incidents become expensive forensics exercises.
Research Finding: Teams with full CI traceability resolve production incidents up to 6x faster than those without it. Faster resolution directly reduces mean time to recovery (MTTR), one of the four core DORA performance indicators.
| DORA Metric | Low Performer Baseline | Elite Team Benchmark | Primary Driver |
|---|---|---|---|
| Deployment Frequency | Once per month or less | Multiple times per day | CI/CD automation and artifact gates |
| Lead Time for Changes | 1 to 6 months | Less than 1 hour | Docs-as-Code and clear DoD |
| Mean Time to Recovery | 1 week or more | Less than 1 hour | Runbooks and CI traceability |
| Change Failure Rate | 46-60% | 0-15% | Binary DoD and automated testing |
4. Runbooks
A runbook answers one question: “What do I do when this breaks?”
It must exist before a service goes to production. It must be maintained as the service evolves. It must be written for an engineer who has never seen the service before.
The test for a functional runbook is direct:
- Can an on-call engineer follow it at 3am without escalating to the author?
- Does it cover rollback steps, not just fix steps?
- Is it version-controlled alongside the codebase it describes?
If the answer to any of these is no, it is not a runbook. It is a rough note. Rough notes do not survive incidents.
5. Docs-as-Code
Wikis fail for one structural reason. They are not part of the development workflow. They live outside the pull request. They are updated voluntarily, not by enforcement. Within 90 days of any major system change, a wiki entry is unreliable.
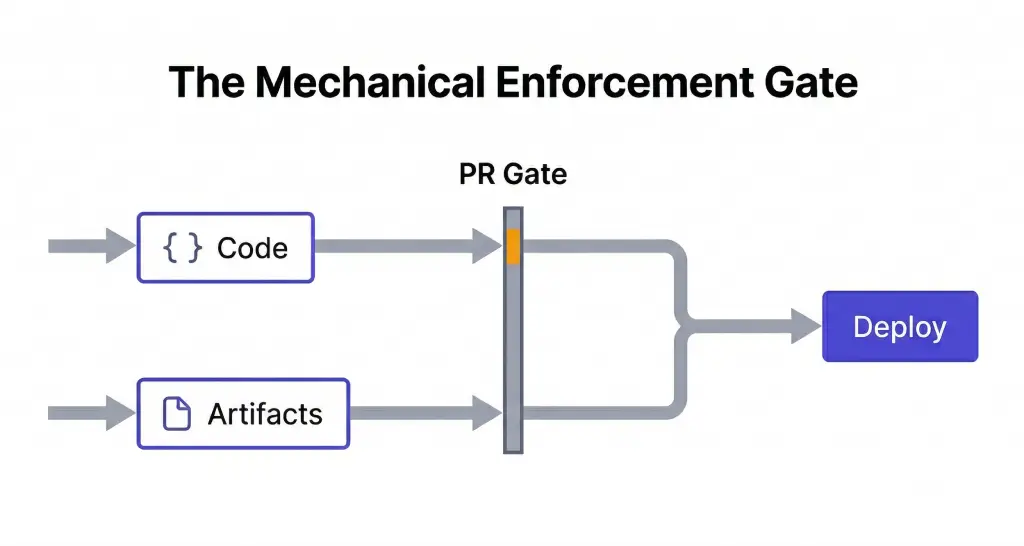
Docs-as-Code moves documentation into the repository. Specs, architecture decisions, onboarding guides, and runbooks all live in /docs. All changes are reviewed via PR. No code ships without its accompanying documentation update.
| Approach | Version‑Controlled | Enforced via PR | Searchable | Stays Current |
|---|---|---|---|---|
| Wiki (Confluence, Notion) | No | No | Partial | Rarely |
| Inline Code Comments | Partial | Partial | No | Sometimes |
| Docs‑as‑Code (Repo) | Yes | Yes | Yes | By design |
This is the only documentation model that keeps pace with a fast-moving codebase.
The Seven Diagnostic Questions
Before any infrastructure investment, run this internal audit. These questions identify your current exposure.
☐ What blocks your engineering team at 5pm on a Friday?
☐ Can you trace any production incident to its root commit in under 2 minutes?
☐ What percentage of your open tickets have explicit, verifiable acceptance criteria?
☐ How long does it take a new engineer to ship their first PR without senior supervision?
☐ Can an on-call engineer resolve your top 5 incident types without escalating to the original author?
☐ What artifact allows a decision to be rolled back without the original decision-maker present?
☐ When was your team’s documentation last updated as part of a formal PR review?
If more than two of these expose gaps, the management tax is already compounding in your system.
How Techkraft Enforces This by Default
Most engineering firms treat documentation as a recommendation. Techkraft treats it as a structural gate.
Every Techkraft pod operates with the following non-negotiable conditions:
- RFC required before any complex or cross-system work begins. No RFC, no start.
- Binary DoD required on every ticket before it enters sprint planning. No criteria, no sprint.
- Docs-as-Code PR gate enforced on every repository. No documentation update, no merge.
- Runbook required before any new service is promoted to production. No runbook, no deploy.
- CI traceability enforced across all pipelines with full commit-to-ticket linkage.
This is not aspirational. These are the operating conditions of every engagement, by default.
The result is distributed engineering that does not require a client-side project manager to function. The artifacts replace the management layer.
The structural advantage: Techkraft pods operate across time zones without synchronous standups because the artifact layer carries the context. Engineers in Kathmandu and London work from the same version-controlled truth. The pods are self-directing by design, not by exception.
This is the difference between staff augmentation (people who need direction) and an artifact-driven pod (a system that generates direction from structured inputs).
From Architecture to Autonomy
The path from a high-friction distributed team to a high-autonomy one follows a predictable sequence:
Artifacts create clarity. Clarity removes blockers. Fewer blockers reduce management overhead. Lower overhead creates autonomy. Autonomy scales.
Teams that treat this as a cultural initiative fail consistently. Culture is fragile. Systems are not.
The Artifact-First Operating System works because it does not rely on discipline or goodwill. It relies on enforced gates:
- The RFC must exist or the ticket does not start.
- The runbook must exist or the service does not ship.
- The DoD must be binary or the PR does not merge.
Replace trust with proof. That is the model.
If your current distributed engineering setup requires daily standups, constant Slack monitoring, or senior engineers reviewing offshore output line-by-line, the problem is not the team. The problem is the absence of an artifact layer.
Fix the system. The people will follow.
Stop Managing. Start Shipping.
Stop fixing “outsourced” spaghetti code.
Deploy an ISO 27001-certified engineering pod that hits your internal linting standards and security benchmarks from Day 1.